covid19stats is an app designed to help visualize the spread of COVID-19 in America. It also demonstrates how different technologies can all work together.
Table of Contents
About The Project
The app was initially used to simply import US infection data into PostgreSQL, overtime the data was made available to be visualized with a Flask web app.
Built With
Prerequisites
Install the required pip packages.
- virtualenv
pip3 install virtualenv
virtualenv env
source env/bin/activate
Installation
This guide serves as a good foundation to initialize the project.
A postgresql server must be running with user postgres and password root. A database named covid should be created.
Clone the repo.
git clone https://github.com/orlovcs/Scrappy.git
cd Scrappy
Head into the virtual env.
source env/bin/activate
Install all the requirements for pip.
pip3 install -r requirements.txt
Set the env vars from .env.
export APP_SETTINGS="config.DevelopmentConfig"
export DATABASE_URL="postgresql://postgres:root@localhost/covid"
The chrome driver used by selenium must be installed locally and the binary must be set to the GOOGLE_CHROME_SHIM env var:
export GOOGLE_CHROME_SHIM="path/to/chromedriver"
The app pulls data from datahub.io into a pandas df and uses it to create a table with information for each state/province as well as a table for the total cases for the country.
To refresh the table data, execute data.py :
python data.py
As of May 24, 2020, the original data is composed of nearly 380,000 rows while the the total row count for the tables generated by data.py come out to 7,257.
Usage
After the tables are created the local server can be started in the virtual env by running:
python manage.py runserver
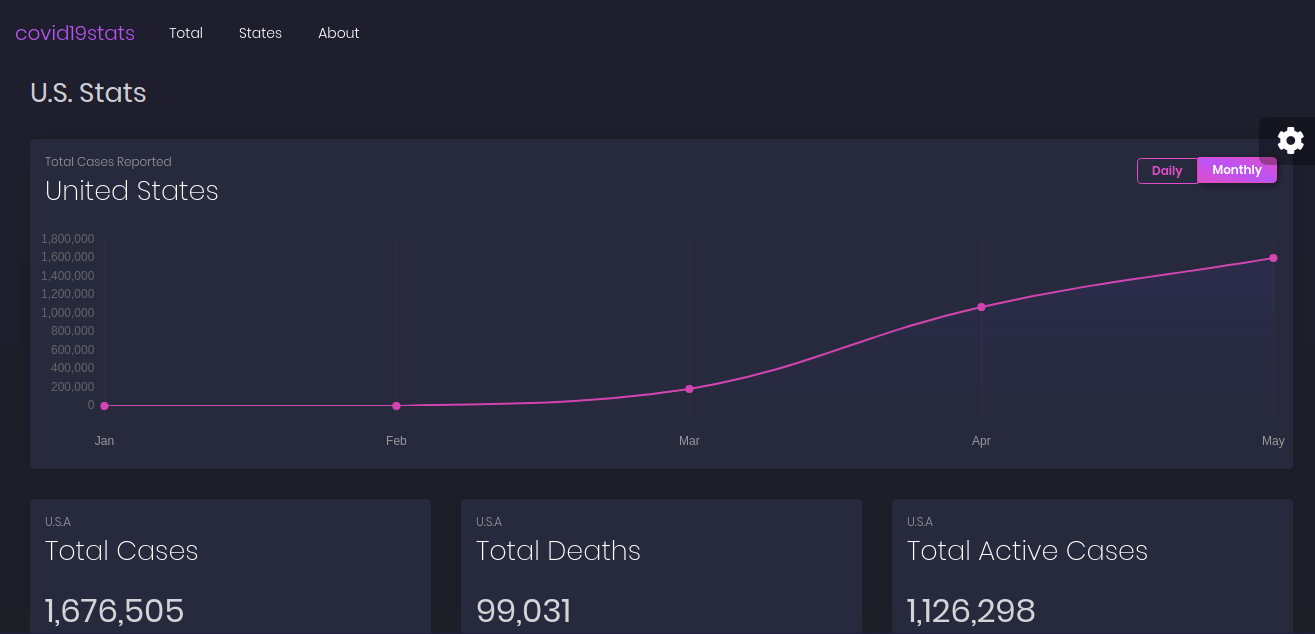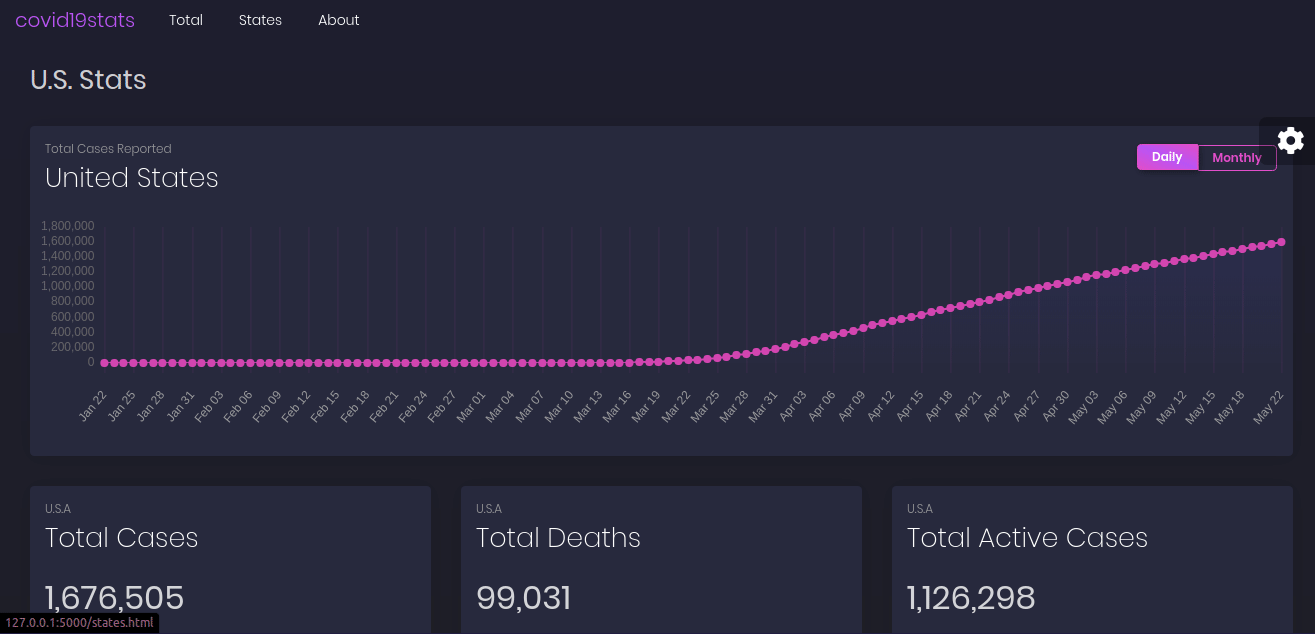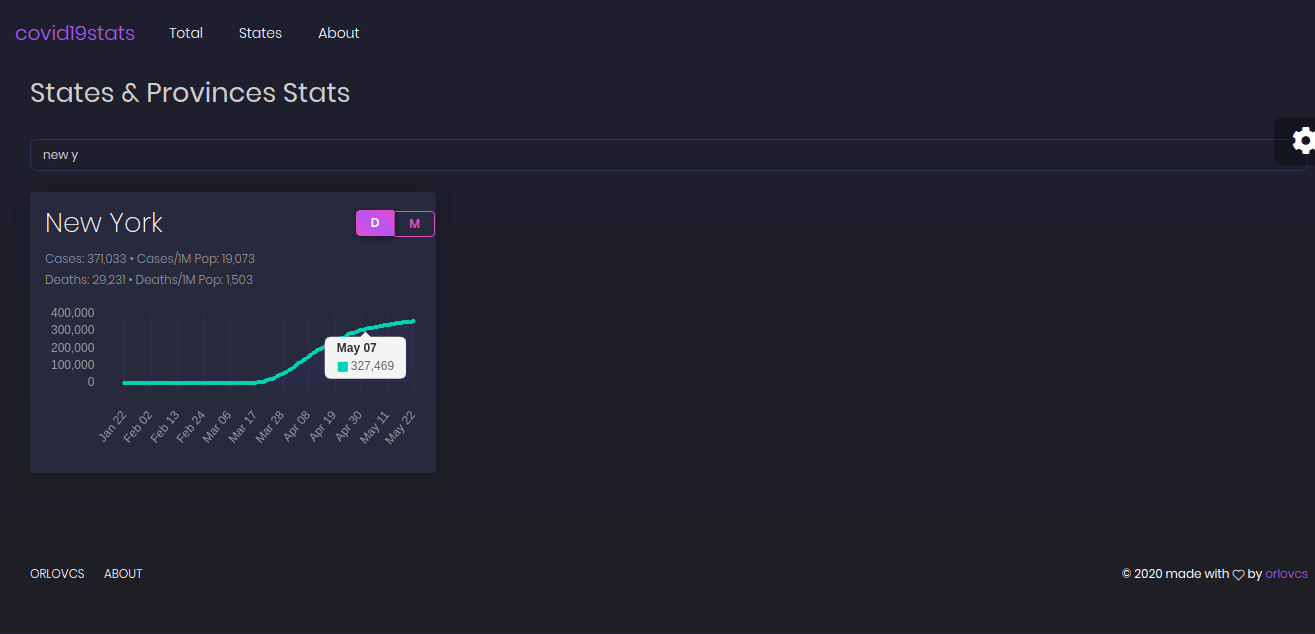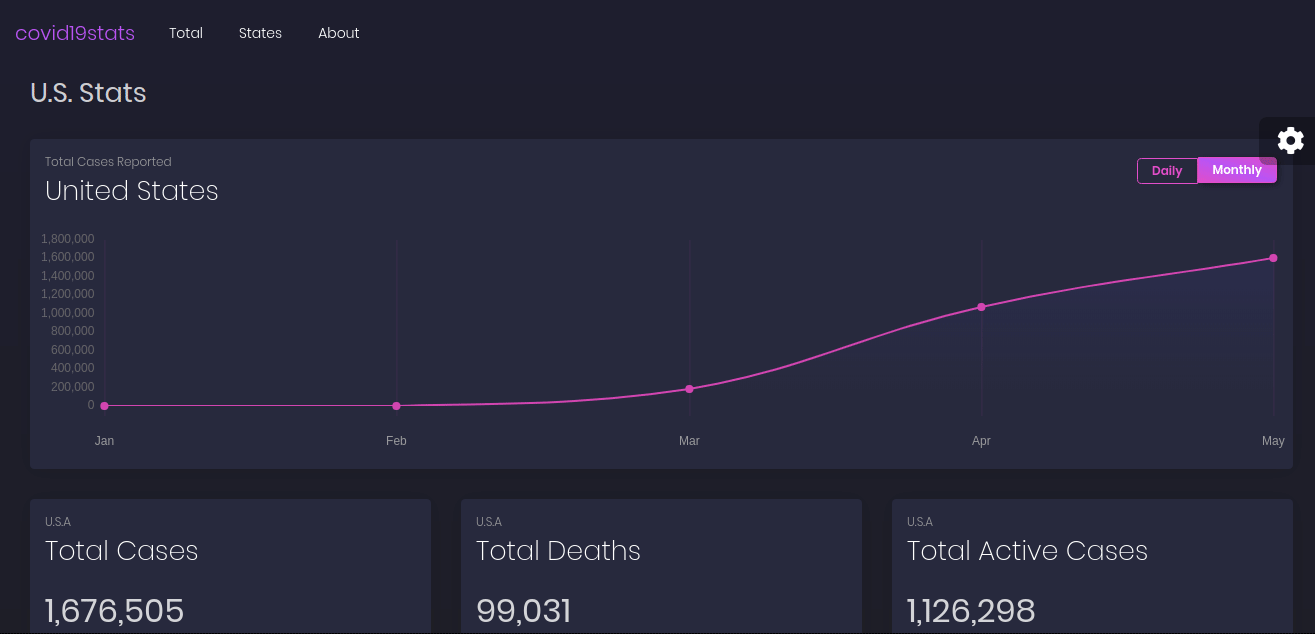
The main page gives an overview of the total data for the U.S. while the states page provide a searchable overview for each state.
If the command returns that the address is already in use, find and kill all existing instances:
ps -fA | grep python
kill -9 pid
python manage.py runserver
API
An endpoint is available to manually trigger a data refresh on the server. The endpoint triggers a subprocess which calls on data.py to execute in the background. This is done since waiting for the data refresh during the request causes it to timeout.
The endpoint can be called with a PUT request on the root URL:
curl -i -X PUT http://localhost:5000
Development
See progress.
Docker
The included Docker Compose files will allow you to run the app in a container with just the two following commands:
sudo docker-compose build
sudo docker-compose up
Initially there was an attempt to utilize the chromedriver container but it turned out to be easier to download Chrome 83 and the respective chromedriver directly into the base image using the package manager during the building process. This version of Chrome was isolated to work with the version of Selenium used. This was used as a initial reference for the Dockerfiles and this was used to install the chromedriver correctly.
Heroku
To deploy this app to Heroku, install heroku-cli
curl https://cli-assets.heroku.com/install.sh | sh
Log into the CLI and deploy the app by following these docs.
Row Compliance
Since a free account is limited to 10,000 rows, the original dataset needed to be aggregated by precomputing and summing up the cases for each day and then specifying this data by state. With this reduction the app can exist and function normally with under 10,000 rows, instead pulling data from a table created for each state/province. However as the data continues to grow, eventually the tables would be forced to drop the top rows after checking if they are over row capacity.
Chromedriver
The headless chromedriver must be installed as the following buildpacks for the dyno:
https://github.com/heroku/heroku-buildpack-chromedriver
https://github.com/heroku/heroku-buildpack-google-chrome
Locally the headless chromedriver used for selenium web scraping runs without issues. However, on the dyno the chromedriver is unstable and appears to crash the dyno for the first couple minutes of every new version. After some time passes, it no longer crashes.
Data Refresh
The database tables can be refreshed from the upsteam repo by executing data.py on the dyno itself:
heroku run python data.py --app YOUR_APP_NAME_HERE
As well as dumping the local sql file and uploading it to the dyno manually:
pg_dump covid > updates.sql
heroku pg:psql --app YOUR_APP_NAME_HERE < updates.sql
Todo
See open issues.
License
Distributed under the GPL3 License.
Acknowledgements
- datahub.io for main csv data
- worldometers for additional data
This app has been deprecated.
Access the code here.